
 官方微信
官方微信





 資訊頻道
資訊頻道當前,多模態大語言模型(MLLMs)在處理涉及視覺、語言和音頻的復雜任務中取得了顯著進展,但現有的先進模型仍然缺乏與人類意圖偏好的充分對齊,即無法高質量地按照人類偏好習慣理解并完成指令任務。現有的對齊研究多集中于某些特定領域(例如減少幻覺問題),而是否通過與人類偏好對齊可以全面提升多模態大語言模型的各種能力仍是一個未知數。
為探究這一問題,中國科學院自動化研究所聯合快手、南京大學建立了MM-RLHF——一個包含12萬對精細標注的人類偏好比較數據集,并基于此數據集進行多項創新,從數據集,獎勵模型以及訓練算法三個層面入手推動多模態大語言模型對齊的發展,全面提升多模態大語言模型在視覺感知、推理、對話和可信度等多個維度的能力。

MM-RLHF數據集包含三個維度的打分、排序、文本描述的具體原因以及平局等標注。所有標注均由人類專家完成。與現有資源相比,該數據集在規模、多樣性、標注精細度和質量方面均有顯著提升。以此為基礎,本研究提出了一種基于批判的獎勵模型(Critique-Based Reward Model),該模型在評分之前先對模型輸出進行批判分析,相比傳統的標量獎勵機制,提供了更具可解釋性、信息量更豐富的反饋。此外,團隊提出動態獎勵縮放(Dynamic Reward Scaling)方法,根據獎勵信號調整每個樣本的損失權重,從而優化高質量比較數據在訓練中的使用,進一步提高了數據的使用效率。

MM-RLHF數據集
研究團隊在10個評估維度,27個基準測試上對提出的方案進行了嚴格評估。結果表明,模型性能得到了顯著且持續的提升。比較突出的是,基于提出的數據集和對齊算法對LLaVA-ov-7B模型進行微調后,其對話能力平均提升19.5%,安全性平均提升60%。
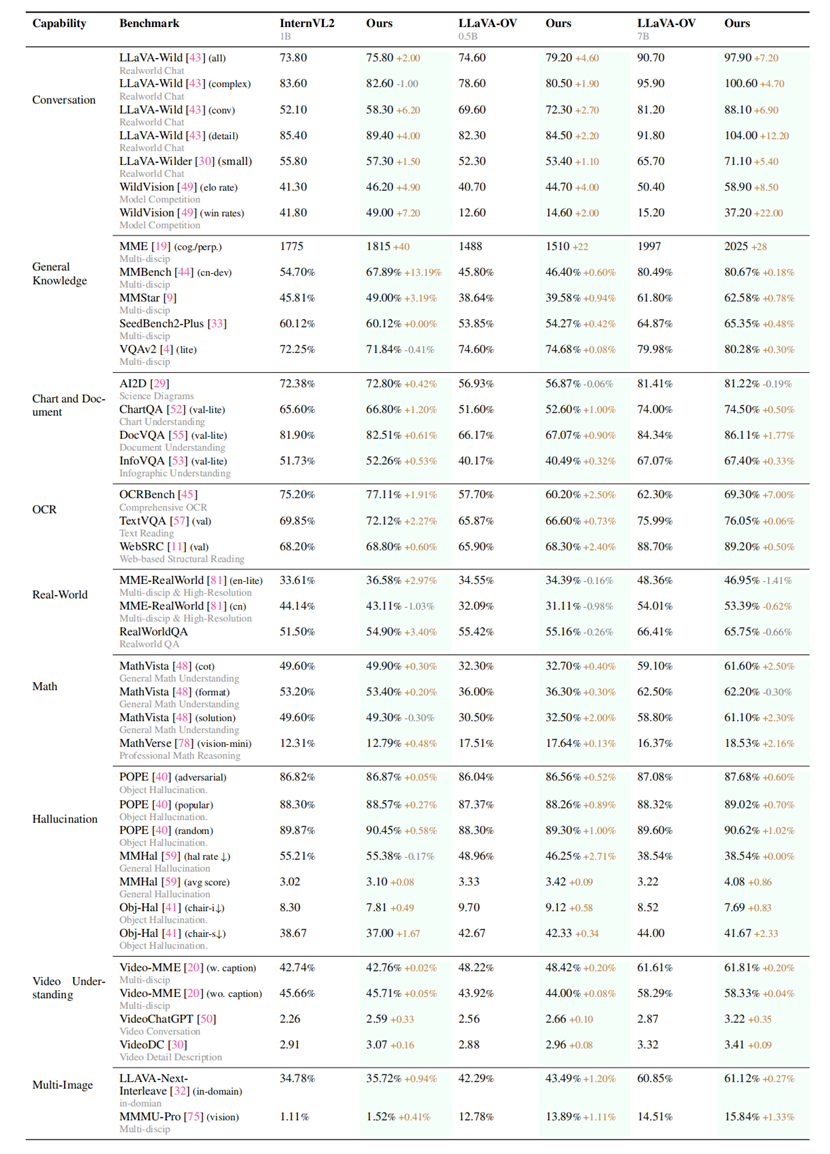
全面評估結果
本研究充分展示了高質量、細粒度數據集MM-RLHF在推動多模態大語言模型對齊工作上的巨大潛力。下一步,研究團隊將將重點利用數據集豐富的注釋粒度與先進的優化技術,結合高分辨率數據來解決特定基準的局限性,并使用半自動化策略高效地擴展數據集。這些努力不僅將推動多模態大語言模型對齊到新的高度,還將為更廣泛、更具普適性的多模態學習框架奠定基礎。
MM-RLHF數據集、訓練算法、模型以及評估pipeline均已全面開源。
項目主頁:https://mm-rlhf.github.io
來源:中國科學院自動化研究所

 北京市公安局海淀分局備案號:11010802023656號
北京市公安局海淀分局備案號:11010802023656號